Batch data generation
Within the simulator, one class is defined as the ‘batch’ and it can be used to simulate batch reactors with defined kinetics.
First, the package is loaded and available default examples are displayed using show_implemented_examples method.
[1]:
from insidapy.simulate.ode import batch
batch().show_implemented_examples()
[+] The following examples are implemented in this BATCH class:
+----------------------+----------------------------------------------------------------------------------+
| Example ID string | Description |
+----------------------+----------------------------------------------------------------------------------+
| batch1 | Batch fermentation with 3 species. Bacteria growth, substrate consumption and |
| | product formation. Mimics the production of a target protein. |
| batch2 | Batch fermentation with 4 species. Bacteria growth, nitrate/carbon/phosphate |
| | consumption. Mimics a waste water treatment process. |
| batch3 | Enzyme substrate interaction described by the Michaelis-Menten model. 4 species. |
| | E + S <-[k1],[ki1]-> ES ->[k2] E + P |
| batch4 | Series of reactions. 3 species. A -[k1]-> B -[k2]-> C. |
| batch5 | Van de Vusse reaction. 4 species. A -[k1]-> B -[k2]-> C and 2 A -[k3]-> D. |
| batch6 | Batch fermentation with 7 species: Biomass (total, viable, death cells), |
| | glucose, glutamine, lactate, and ammonia. Mimics CHO cell growth in reactor. |
+----------------------+----------------------------------------------------------------------------------+
Next, one can decide to use one of the implemented examples or define a new one. In this case, the example of a batch fermentation with 3 species is used ('batch1'). Each example would be fully defined with default values. However, we can overwrite these values by using the corresponding inputs. If we overwrite the default values, we are reminded to check that the given values are in correct order.
[2]:
data = batch( example='batch1', # Choose example. Defaults to "batch1".
nbatches=4, # Number of batches. Defaults to 3.
npoints_per_batch=20, # Number of points per batch and per species. Defaults to 20.
noise_mode='percentage', # Noise mode. Defaults to "percentage".
noise_percentage=2.5, # Noise percentage (in case mode is "percentage")
random_seed=10, # Random seed for reproducibility. Defaults to 0.
bounds_initial_conditions=[[0.1, 50, 0], [0.4, 90, 0]], # Bounds for initial conditions. Defaults to "None".
time_span=[0, 80], # Time span for integration. Defaults to "None".
initial_condition_generation_method='LHS', # Method for generating initial conditions. Defaults to "LHS".
name_of_time_vector='time') # Name of time vector. Defaults to "time".
[!] IMPORTANT: It seems that you changed the default bounds of the species. Make sure the order of the indicated bounds is the following: ['biomass', 'substrate', 'product']
We can now print some information about the example.
[3]:
data.print_info()
[+] Loaded the example BATCH1 with the following properties:
+--------------------------------+------------------------------------------------------------------------+
| Property | Description |
+--------------------------------+------------------------------------------------------------------------+
| Example string | batch1 |
| Example description | Batch fermentation with 3 species. Bacteria growth, substrate |
| | consumption and product formation. Mimics the production of a target |
| | protein. |
| Short reference information | ISBN 0-13-512966-4 |
| Number of species | 3 |
| Species names | ['biomass', 'substrate', 'product'] |
| Species units | ['g/L', 'g/L', 'g/L'] |
| Number of batches | 4 |
| Number of samples | 20 |
| Time span | [0, 80] |
| Time unit | h |
| Noise mode | percentage |
| Noise percentage | 2.5% |
| Lower bounds for experiments | [0.1, 50.0, 0.0] |
| Upper bounds for experiments | [0.4, 90.0, 0.0] |
+--------------------------------+------------------------------------------------------------------------+
This might be useful to use the example in a publication (use the short reference information given to reference where the example came from) or to check if the example is defined as intended.
After that, we can run the experiments to create some in-silico data using the run_experiments method. We can then for example check the data of the first experiment.
[4]:
data.run_experiments()
print(data.y_noisy[0])
[+] Experiments done.
time biomass substrate product
0 0.000000 0.209931 75.317747 0.066468
1 4.210526 0.412243 70.274789 0.024264
2 8.421053 0.977525 68.432262 0.902232
3 12.631579 1.328248 61.199162 1.619636
4 16.842105 1.456481 54.647587 3.486157
5 21.052632 2.304200 46.356629 5.382192
6 25.263158 3.096617 34.720784 6.968374
7 29.473684 3.642308 23.468698 8.556058
8 33.684211 4.521516 14.253261 10.275535
9 37.894737 5.027557 8.758139 11.159293
10 42.105263 5.280977 4.734118 12.172444
11 46.315789 5.185576 1.282952 12.280378
12 50.526316 5.597395 1.225398 12.236056
13 54.736842 5.538414 0.024317 12.101252
14 58.947368 5.521777 2.407662 12.260585
15 63.157895 5.454142 -0.574597 12.511703
16 67.368421 5.617953 -0.238538 12.145786
17 71.578947 5.642230 -0.296372 12.394362
18 75.789474 5.490113 -0.390336 12.776483
19 80.000000 5.552931 0.133594 12.458358
Most modeling approaches require a training dataset and a separate testing dataset. To generate separate datasets, the user can apply a splitting in an sklearn-manner. There is no default value set. In case the user calls the function, a test_splitratio in the range [0,1) needs to be chosen. The value represents the fraction of the total number of batches generated used for the test set. The data is then splitted and stored in the data object as data.training and data.testing.
[5]:
data.train_test_split(test_splitratio=0.2)
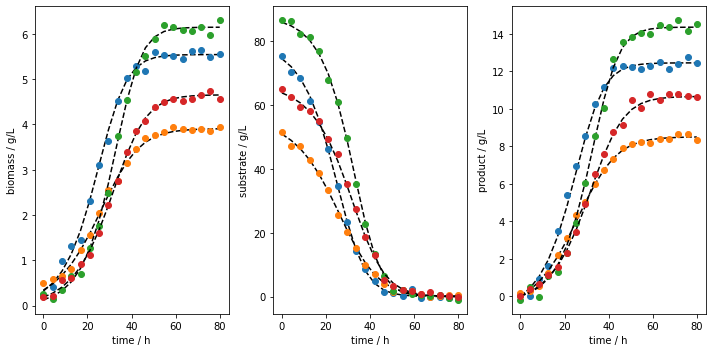
We can now plot the experiments. The fist way to do so is to plot all the runs using the plot_experiments method. The method lets us save the figure using a path (save_figure_directory), a name (figname) and an some extensions (save_figure_exensions) as a list. By using show=False, the plot will not be displayed in a running code.
[6]:
data.plot_experiments( save=True,
show= False,
figname=f'{data.example}_simulated_batches',
save_figure_directory=r'.\figures',
save_figure_exensions=['png'])
[+] Saving figure:
->png: .\figures\batch1_simulated_batches.png
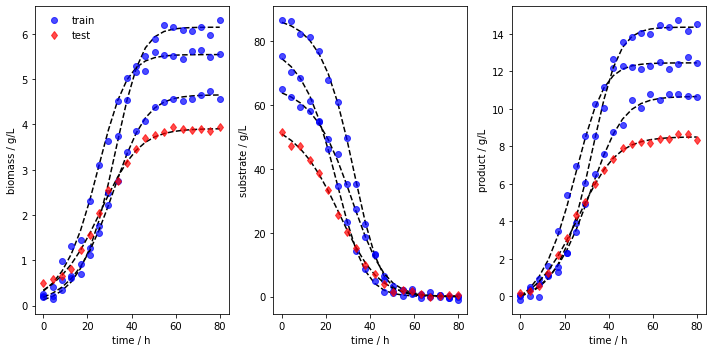
We can also visualize the training and testing runs individually using the plot_train_test_experiments method.
[7]:
data.plot_train_test_experiments( save=True,
show=False,
figname=f'{data.example}_simulated_batches_train_test',
save_figure_directory=r'.\figures',
save_figure_exensions=['png'])
[+] Saving figure:
->png: .\figures\batch1_simulated_batches_train_test.png
After the simulation, one can export the data as XLSX files. By choosing which_dataset to be training (only executable if train_test_split was applied), testing (only executable if train_test_split was applied), or all (always executable), the corresponding data is exported to the indicated location:
[8]:
data.export_dict_data_to_excel(destination=r'.\data', which_dataset='all') # Exports all the data
data.export_dict_data_to_excel(destination=r'.\data', which_dataset='training') # Exports the training data (blue circles in Fig 2)
data.export_dict_data_to_excel(destination=r'.\data', which_dataset='testing') # Exports the training data (red diamonds in Fig 2)
[+] Exported batch data to excel.
-> Dataset: ALL (options: training, testing, all)
-> Noise free data to: .\data\batch_batch1_all_batchdata.xlsx
-> Noisy data to: .\data\batch_batch1_all_batchdata_noisy.xlsx
[+] Exported batch data to excel.
-> Dataset: TRAINING (options: training, testing, all)
-> Noise free data to: .\data\batch_batch1_training_batchdata.xlsx
-> Noisy data to: .\data\batch_batch1_training_batchdata_noisy.xlsx
[+] Exported batch data to excel.
-> Dataset: TESTING (options: training, testing, all)
-> Noise free data to: .\data\batch_batch1_testing_batchdata.xlsx
-> Noisy data to: .\data\batch_batch1_testing_batchdata_noisy.xlsx